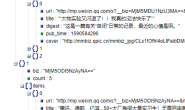
- 获取所有帮助文档的链接,这个比较容易,手动从 vue 官网的侧边栏保存即可,参考下图,把包含所有网页列表的 html 源代码保存为 vuelist.txt。
- 使用 BeautifulSoup 库从 html 中提取所有网页的链接,逐个打开。
- 对每个网页执行一段 js 去掉最上方固定层,避免有部分文字被覆盖。
- 将网页转化为 pdf,并以序号+标题的形式保存。
import os,sys
import playwright
from playwright.sync_api import sync_playwright
from time import sleep
from bs4 import BeautifulSoup
'''
1.如果选择“组合式”,需在打开第一页时手动在网页中点一下
2.vuelist.txt 是通过 chrome 开发者工具中手动复制保存侧边栏文章列表相关的 html 实现,即选择 <nav id="VPSidebarNav"
3.vue 官网的设计比较好,打印为 pdf 只打正文内容,但打其他网站时可能需要酌情调整,比如先执行自定义 js
参考网址 https://playwright.dev/python/docs/api/class-page
'''
jstxt = 'document.getElementsByClassName("VPNav nav-bar")[0].remove()'
pageMode = "A4" #对应纸的尺寸,
#读取 txt 文件
def ReadFile(filepath):
with open(filepath, 'r', encoding='utf-8') as f:
all_the_text = f.read()
return all_the_text
def Run():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.set_default_timeout(20000) #设置网页加载超时时间
page.emulate_media(media="screen")
txt = ReadFile("vuelist.txt")
bsobj = BeautifulSoup(txt,"lxml")
all_a = bsobj.findAll("a")
idx = 0
for item in all_a:
url = item.attrs.get('href')
if url is None or len(url) < 2:#某些 a 标签可能没有 href
continue
url = "https://cn.vuejs.org" + url #相对 url 需要补全
title = item.get_text()
if "?" in title: #处理标题中有特殊字符的,不一定要略过
continue
print(idx,title,url) #方便查看实时进度
idx += 1
pdfname = pageMode + "_" + str(idx) + "_" + title + ".pdf" #我习惯这样命名,方便排序和查看,您也可以自行修改
if os.path.exists(pdfname): #程序运行时有可能中断,重新开始时略过已经保存的
continue
page.goto(url)
sleep(5)
page.evaluate(jstxt)#执行 js,把最上方的固定层删除,否则生成的文档中会有部分内容丢失
sleep(2)
page.pdf(path = pdfname, format = pageMode,margin={"top":"28px","bottom":"28px"}) #还有许多可以设置的参数,详见参考网址
if __name__=="__main__":
Run()
- vue 官网教程 https://cn.vuejs.org/guide/introduction.html
- playwright 官网 https://playwright.dev/python/docs/api/class-page
- pdf 合并软件 https://editor.foxitsoftware.cn/?agent=foxit&MD=menu
下面是我开发的其他小工具,欢迎使用