一步步教你打造文章爬虫(1)-综述
本系列我将与大家一起学习批量下载任意公众号所有历史文章。
争取讲明白,源代码也会随着教程逐步放出来,但是不喜欢伸手党和不过如此党(凡事都说虽然我不会但我觉得不难的人)。
用户需要有一定的基础:
- 知道百度这个神奇的网站,而且知道是免费的。
- 遇到问题先自行尝试解决,不要张口就问。
- 有 html 基础(可去 http://www.runoob.com 学习)。
- 有 python 基础,会用 pip 安装第三方库(强烈建议新手去http://www.liaoxuefeng.com 看免费版教程,里面也包含了如何在电脑上安装配置 python)
- 会用 chrome 的开发者工具。
会了第 1、2 条,则第 3、4 条应该可以搞定。第 5 条在本文会讲到基础用法。
先请由本人扮演的政委讲两句:
先说点成果给大家点信心:本人 2 年前就已经用 python 完整实现了批量下载任意公众号历史文章的功能,1 年前又用 C#重写了整个功能,做出了界面漂亮的软件。为了避免让小白误以为本教程的终极目标是做一个图形化的软件我就不贴图了。本教程是用 python 代码实现批量下载功能,没有图形界面。重要的是让大家体会到整个过程中的思路,这样将来你想保存其他任何网站都不再是难事。
本人非计算机科班出身,在第一遍开发这套软件的过程中走了许多弯路,踩了许多坑,虽然现在依然是个小白,但至少可以为大家理出一条稍好走的路。为方便大家理解和操作,有的地方会采用麻烦点但好理解的方案。
本教程的目的是让有一定编程基础,想自己写个爬虫,但是不知从何下手,或者多次尝试过但多次卡壳的朋友能快速搭建出一个完整的系统。
我将尽量接地气、以最简洁的形式实现所有功能,所以,不要担心完不成,多一点坚持,多给自己打打气。
下面请由本人扮演的老兵给参加本次特训营的朋友们开始讲解:
公众号文章不管是在 PC 端还是手机端还是浏览器中,其实都是以网页的形式呈现的,而保存电脑上的网页版最为方便。
工欲擅其事必先利其器,为照顾大多数人能听懂下面可能有点啰嗦,但不难,而且学会了对以后大有帮助。
想下载网页就要先研究网页,它是由什么组成的?从哪里来的?
在 chrome(QQ 浏览器、360 浏览器中应该有类似选项,但不推荐用 IE)中打开任意一篇公众号文章。
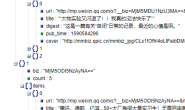
按 F12 键,或者在网页上右键->"检查",将打开如下图所示的一个窗口,这个窗口的最左上角文字是"DevTools"直译为"开发者工具",下面会经常提到。有的电脑上可能是将网页窗口一分为二,下半部分弹出这个开发者工具窗口。显示方式的不同可以通过点下图中右上角的三个点切换,读者视自己的电脑屏幕大小适当选择即可。
-综述")
再看上图的第一行有许多标签,我们需要用到"Elements","Network"两个标签。
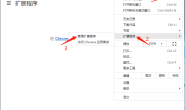
先点"Elements",会看到许多有层次的格式化过的代码,这其实就是网页的 html 元素结构。先点击下图红框所示的小图标,然后将鼠标移动到文章的正文段落处,发现文字自动被选中一块,同时右侧会有一段与之对应的代码也会变背景色。通过这种方式将源代码与最终呈现的内容一一对应起来,这也是网页编辑人员在调试时经常用到的方法。
-综述")
来点有趣的,双击右侧源代码中的"一周前",然后将其修改为 "1986-01-01",回车,看看日期那里是不是也变了?其实许多装 X 的网页截图都不需要用 PS,直接这样改源代码就可以了。
如果再刷新一下网页,会发现刚才修改的内容又回到原始状态了,因为我们刚才只是修改本地的内容,而刷新是从微信的服务器上又重新获取了原始网页。否则,如果我能这样在银行网站修改我的银行存款就好了,哈哈。
再回到开发者工具窗口,点"Network"标签,按 F5 刷新网页(一定要先打开开发者工具再加载网页它才能监测到数据的加载),会看到下面飞快得列出许多内容。不知道是些啥玩意?其实这是一个网页要正常显示需要下载的所有文件(比如图片,css 样式表,js 脚本等),一个看似简单的网页背后可能是由许多文件组成的(当然也可以只有一个文件),而我们要保存文章正是要把每一行所列出来的文件都保存下来。
单击第一行(一定是第一行),窗口将变成下图,在这个窗口的右半部分会列出当前选中的这一行的详细请求内容。
下图红框中有一排标签栏,不要抓狂,把这组标签看完略枯燥的内容就结束了^_^
先点 Preview 标签,好像显示了一个网页,再点 Response 标签,好像是一个网页的源代码?对的,Response 是原始代码,Preview 是将代码转化成网页。
-综述")
那么,原始代码是怎么来的呢?点 Headers 标签,看下图,天呐,又是一堆英文,不急不急,都是些常见单词,而且这些代码其实是分三大块,分别为"General"、"Response Headers"、"Request Headers",(当然有时候还会有更多块)
-综述")
谢天谢地,只需要看这三大块的名字就可以了,不需要看里面的内容。而这些数据块正是对应着浏览器加载网页的流程:
- General 包含要向微信服务器请求的基础数据,比如请求的网址,请求的方式。
- Request Headers 中也是包含请求信息,比如浏览器是手机版的还是电脑版的,当前电脑环境是英文的还是中文的,有的需要会员登录才能看的还会带上会员信息(当然是加密过的)
- 浏览器把这些请求数据准备好,一起发送给微信服务器。微信服务器收到之后会在后台找到这篇文章,并发回给浏览器。
- 浏览器会先检查返回的 Response Headers,可以把它理解成返回的一本书的封皮,上面会写着你想请求的那篇文章是返回成功了还是失败了,文章一共有多长,等等。
- 那我想看的文章呢?就是你刚才看到的 Response 标签里的那一堆代码。浏览器会把它转换为最终网页的形式。
我花了许多篇幅向大家介绍 chrome 开发者工具,是因为这是爬虫开发必备技能,但它又不是只能为爬虫开发者所用,希望大家能多多尝试,反正怎么搞又搞不坏,其中有趣的技巧还有许多哦。
小结:
- 学会使用 chrome 开发者工具分析和调试网页。
- 对网页的加载流程有初步认识。
- 有所收获又似懂非懂中对接下来的学习有所期待
其实写这种教程极易陷入明白的人不需要看,不明白的人看了依然不会的情况,所以我要讲得足够详细,为了防止读者看睡着了又得适当精炼。第一次写教程,请多担待。
接下来的章节就好办了,因为有代码写,有数据显示,相对来说生动了许多。
本文会同步在多个平台,由于有的平台发文后不可修改,所以勘误和难点解释请注意查看文后留言,也可以点击"阅读原文"查看我的个人博客版。
打算建个 github 项目,把代码都上传上去,也考虑建个 QQ 交流群。会在后续文章中公布这些信息。对于本系列课程有啥建议也欢迎留言。
关注本号,查看后续更新。