-下载网页")
书接上文,今天一起来学习把网页版文章下载到本地电脑上。
前面讲过,请求网页的流程是浏览器先向服务器请求 html,服务器返回 html,浏览器分析这个 html,发现 html 中还需要一堆的 js,css,图片,然后浏览器再去下载这些文件,最终组装成一个完整的 html 页面。
所以,第一步,要把这个 html 下载下来。
是时候请出大家期待已久的 python 了,我在讲解的过程中只列出核心代码,完整代码会列在文章最后,所以强烈建议先把整篇文章看完了再动手自己敲代码。其他文章也是相同的逻辑,以后不再重复。
需要用到一个鼎鼎大名的第三方库 requests ,用它来模拟浏览器给微信服务器发送请求和接收请求。
那么发送的请求中都要包含什么内容呢?
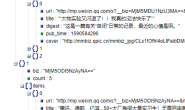
上文介绍 chrome 开发者工具时提过这个问题,奥秘在 Headers 这个标签中,见下图,理论上来讲 chrome 浏览器发送了什么我们的最好就原样照着用 python 发送什么,即把下图所示的 General 和 Request Headers 块中的参数全都发送出去。但多数时候并不需要这样,特别是对于 get 请求,一般只需要少数几个参数即可,但是请注意 User-Agent 这一项一定要改得跟 chrome 一样。其他细节不再多述,过后您操作的多了自然会明白。
-下载网页")
简单的注释会直接在代码中列出,复杂的会在代码后面用文字再解释,另外本文的原始稿是在微信公众号后台编辑生成的,直接复制粘贴到其他平台格式会全乱掉,所以使用了图片的形式,见谅。
-下载网页")
运行上面代码之前,请先手动在 C 盘下新建 vWeChatFiles 文件夹,本项目之后下载的所有文件都放在此目录下,请注意这里是保存下载的网页文件的,而你的 python 源代码可以放在其他目录下。
运行上面的代码,你将看到屏幕刷刷得显示一堆网页源代码,并且在 c:/vWeChatFiles 文件夹下生成一个 test.html 文件。
下面,来看这个下载下来的 test.html 能否正常工作,请先打开 chrome,按 F12,弹出开发者工具,在最上面一行标签中切换到 Network,然后在 chrome 的网页中输入 C:/vWeChatFiles/test.html,回车。可能需要等几十秒,看到了刚才我们下载的网页。
同时 chrome 开发者工具显示如下图所示
-下载网页")
有许多行是红色的,表示这些文件下载失败了,刚才之所以等了好久网页才显示出来就是因为浏览器在尝试等待这些文件的下载,等过了一段时间还是没有等到对的人,它说那就算了吧,我只把接收到的内容显示出来。
所以,仔细查看加载出来的 test.html,文字显示正常,格式也正常,但是没图片啊。其实这个图片没显示的原因比较复杂,先不展开讲。
在 test.html 网页的空白处右键,点"查看网页源代码",chrome 中会打开一个新窗口,显示这个网页的原始源代码,此处的源代码,跟用记事本打开 test.html 文件所看到的源代码是一样的。
但是,这些原始代码跟开发者工具中 Elements 中显示的,即下图右侧显示的格式化的网页代码可能不一样。比如下图箭头所指位置的“1 周前”,虽然你在右侧的源代码中也看到了“1 周前”,但是在最原始的代码中此处并没有“1 周前”。
其实右侧显示的代码是原始源代码被浏览器打开之后运行了 js 程序计算出来的网页结构代码。搞明白两种源代码的不同之处,可以帮初学者减少许多迷惑。
-下载网页")
然而奇怪的是,看源代码对应的<img />标签中竟然没有 src 属性,而开发者工具中的<img /> 中的 src 是一堆奇怪的文字,并不像一个网址。(不过至少此处再次印证了上文我说的两处的源代码有可能并不一致)
-下载网页")
稍延伸一下,上图所示的 src 中的一串字符其实是表示一张图片,一张用 base64 文本表示的简单图片,有兴趣的朋友可以自行百度,顺便告诉你一个好消息:百度竟然不要钱。
这些都不管了,直接把 src 改成正确的图片网址吧。可是,图片网址在哪里呢?请再仔细看上面的一张图, data-src 好像是一个网页,把这一串网页复制出来,粘贴到浏览器地址栏中打开,神奇的事情发生了:竟然是文章中的一张高清无码大图。那我们就有理由相信,这就是原本此处要显示的图片的网址,可它为啥藏着掖着,而不是直接给 src 设置好呢?这是个好问题,知道答案的朋友请在文章下方留言,我送你上墙。
下面,就把此网页中所有图片标签<img /> 中的 data-src 的网址赋给 src,需要用到另一个优秀的第三方库 BeautifulSoup,它可以解析网页中的元素,并对它们进行修改、增加、删除等操作。下面只列出了改变过、需要重点查看的部分,并不是完整代码,所以你直接保存复制是运行不起来的,但如果加在上面给出的源代码的后面就能跑起来(当然要小改一些地方,再次提醒读者需要有一点编程基础)。
-下载网页")
注意第 21 行,有的图片会以 //http://res.wx.qq.com开头,需要换成常见的http://res.wx.qq.com 形式开头,否则本地打开网页时这些图片会无法正常加载。至于为什么会有 // 开头的网址您可以自行百度。
C:\vWeChatFiles 文件夹下会有一个 test2.html 文件,在 chrome 中打开,网页可以正常显示了,但是开发者工具中依然显示有许多请求是红字状态,先不用管。
接下来的问题是,虽然图片可以在网页中显示了,但 src 是一个网址,图片是在每次打开网页时从远程服务器下载的,并没有保存到本地,如果远程文章被删了图片就没法看了。
接下来我们要做的是:把图片下载到本地,并在 html 中把图片的 src 指向本地图片的位置。
主要代码如下,需要先在 vWeChatFiles 目录下新建一个 images 文件夹
-下载网页")
至此,网页保存到本地基本完成,其实还有几个小问题,比如:
引用样式表时也是用到了 // 开头的网址,聪明的你仿照图片的修改方法去修改这里应该不是问题,就当是小小的练习了。
又比如:开发者工具中看到许多 js 文件加载失败,但并不影响网页显示,且过后会专门处理 js,所以先不用管。
请注意,本示例代码为了方便大家理解,许多地方用了硬编码,且都堆在一个文件中,这不是最佳方式,甚至可以说是糟糕的方式,但在现阶段代码不多的情况下这不是啥问题,大家先把注意力集中在功能的实现上即可。
本节开始需要写代码,有一定难度了,建了个 QQ 群方便大家交流,群号 7 零 343 一 832 加群暗号 20190731 (可能会变,恕不另行通知)
本文会同步在多个平台,由于公众号等平台发文后不可修改,所以勘误和难点解释请注意查看文后留言,也可以点击"阅读原文"查看我的个人博客版。关注本号,查看后续更新。
本文仅用于技术学习交流,请勿用于非法用途,由此引起的后果本作者概不负责。
#下面这一行一定别忘了
import requests
#定义一个保存文件的函数
def SaveFile(fpath,fileContent):
with open(fpath, 'w', encoding='utf-8') as f:
f.write(fileContent)
#定义一个下载 url 网页并保存的方法
def DownLoadHtml(url):
#构造请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Connection':'keep-alive',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3'
}
#模拟浏览器发送请求
response = requests.get(url,headers = headers)
if response.status_code == 200:#返回码为 200 表示正常返回
htmltxt = response.text #网页正文
print(htmltxt)
return htmltxt
else:
return None
#新添加一个引用
from bs4 import BeautifulSoup
#读取文件
def ReadFile(filepath):
with open(filepath, 'r', encoding='utf-8') as f:
all_the_text = f.read()
return all_the_text
#将图片从远程下载保存到本地
#url:图片网址
#savepath:本地保存路径
def DownImg(url,savepath):
r = requests.get(url)
with open(savepath, 'wb') as f:
f.write(r.content)
#修改网页中图片的 src,使图片能正常显示
#修改网页中图片的 src,使图片能正常显示
def ChangeImgSrc(htmltxt):
bs =BeautifulSoup(htmltxt,"lxml") #由网页源代码生成 BeautifulSoup 对象,第二个参数固定为 lxml
imgList = bs.findAll("img") #找出网页中所有的图片
imgindex = 0 #图片编号,不同图片要保存为不同的名称
for img in imgList:
imgindex += 1
originalURL = "" # 定义一个变量用以保存图片真实 url
if "data-src" in img.attrs:#有的<img 标签中可能没有 data-src
originalURL = img.attrs['data-src']
elif "src" in img.attrs:#如果没有 data-src 但有 src 则提取 src
originalURL = img.attrs['src']
else: #啥都没有则 src 为空吧
originalURL = ""
if originalURL.startswith("//"):#如果 url 以//开始,则需要添加 http:
originalURL = "http:" + originalURL
if len(originalURL) > 0: #有图片网址则下载该图片
print(originalURL)
if "data-type" in img.attrs:
imgtype = img.attrs["data-type"] #文件的扩展名
else:
imgtype = "png" #不知道图片扩展名的情况下默认为 png
imgname = str(imgindex)+"."+imgtype #形如 1.png 的图片名
imgsavepath = "c:/vWeChatFiles/images/"+imgname #图片保存目录,后续要改成相对地址
DownImg(originalURL,imgsavepath) #下载图片
img.attrs["src"] = "images/" + imgname #网页中图片的相对路径
else :
img.attrs["src"] = ""
return str(bs) #将 BeautifulSoup 对象再置换为字符串,用于保存
if __name__ == "__main__":
url = "https://mp.weixin.qq.com/s/tK6jYTTtl8jQI86fysvj4g"
htmlstr = DownLoadHtml(url)
htmlstr = ChangeImgSrc(htmlstr)
savepath = "c:/vWeChatFiles/test3.html" # 先手动在 C 盘下新建 vWeChatCrawl 文件夹
SaveFile(savepath, htmlstr)